Welcome!
I am a mathematician and work as a data scientist at codecentric AG in Münster, Germany. My special interests are machine learning, deep learning and functional programming.
Recently, I’ve been focusing on natural language processing (NLP) — classification of documents, extraction of data, question answering et cetera.
News
14
Dec
2020
Talk
Natural Language Processing — a glimpse into theory and practice
13
Nov
2020
Blog Post
06
Nov
2020
Blog Post
2019-08-07
· english
Improve accuracy of character-level text classification with the deep learning framework Keras, using n-gram extraction inside the model via convolutions.


2019-03-24
· deutsch
In diesem Blog-Post werden wir mit einfachen ML- und NLP-Methoden versuchen, Bundestags-Reden dem Politiker zuzuordnen, der sie gehalten hat.


2019-02-02
· english
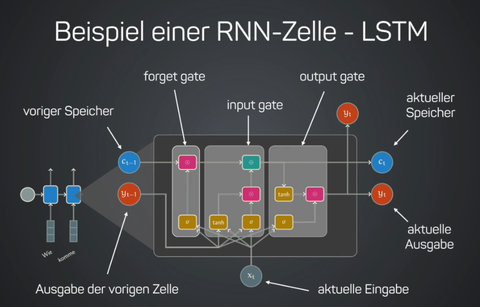
Last week, I finished a new lecture on intent recognition — a branch of natural language understanding — as part of the codecentric.AI bootcamp.
2019-01-29
· english
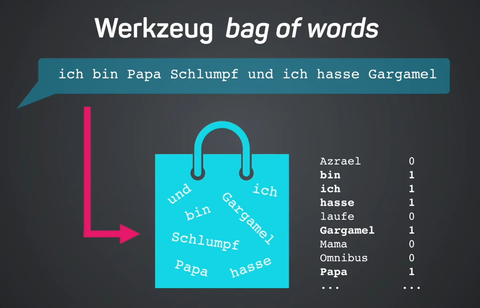
With Bert Besser, Myriam Traub and Veronika Schindler, we prepared an introductory lecture on natural language processing (NLP) as part of the codecentric.AI bootcamp.
2019-01-28
· english
Soon after joining codecentric I got the opportunity to contribute to the upcoming codecentric.AI bootcamp, a learning platform focused on machine learning and deep learning.
2018-10-09
· english
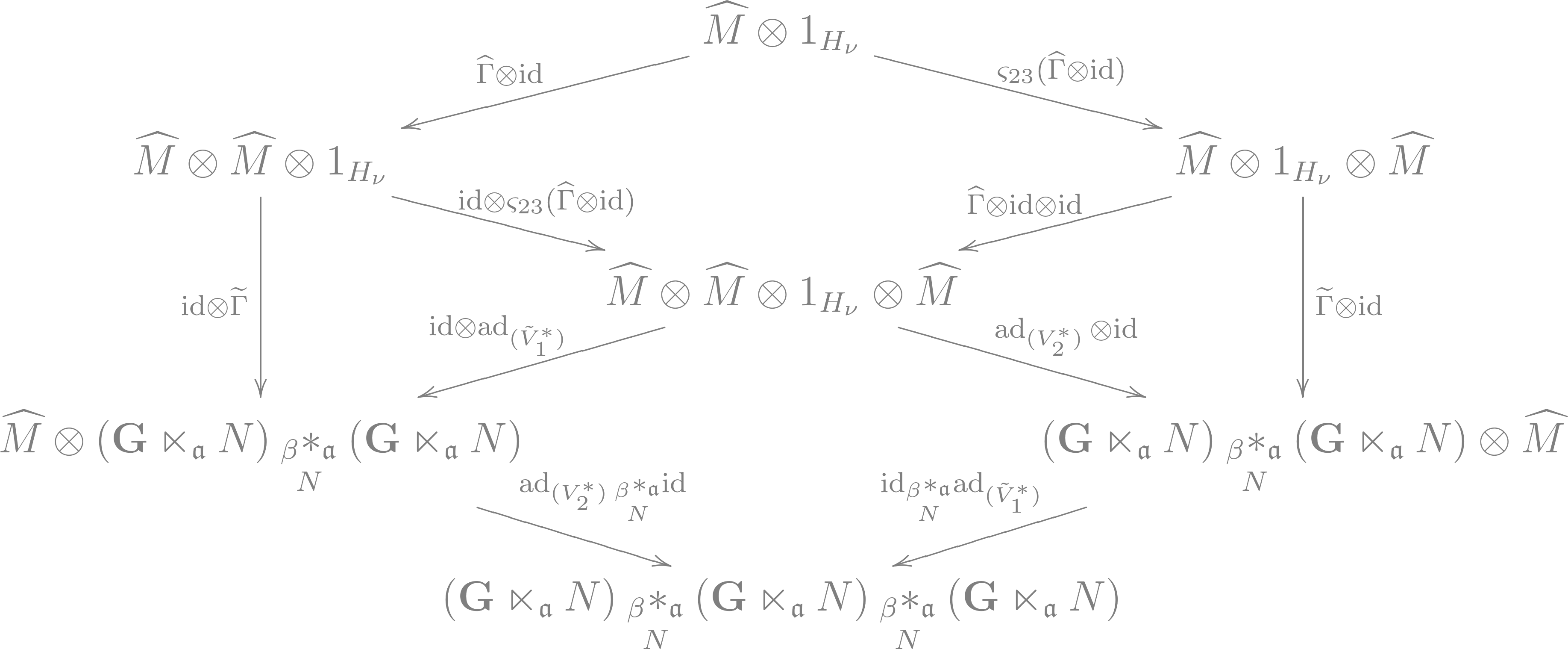
The key idea of category theory is that mathematical objects should be studied in terms of their relations to other objects rather than in isolation, and usually come with some natural classes of maps.



An Introduction to Quantum Groups and Duality
Textbooks in Mathematics, European Mathematical Society (EMS), Zürich, 2008
This textbook provides an introduction to the theory of quantum
groups with emphasis on their duality and on the setting of
operator algebras. It addresses graduate students and
non-experts from other fields.
→publisher's website